
行业动态
近年来,大模型技术热潮中对数据质量的要求提升到了一个新的高度。与此同时,人们也在探索大模型本身能否助力于数据清洗与数据治理等工作。本文将从技术的角度展望大模型驱动的数据治理技术,并分享此领域的一些研究热点。
主要内容包括以下几个部分:
1.以数据为中心的人工智能
2.大模型预训练中的数据工程
3.大模型驱动的数据治理技术
4.总结与展望
01 以数据为中心的人工智能
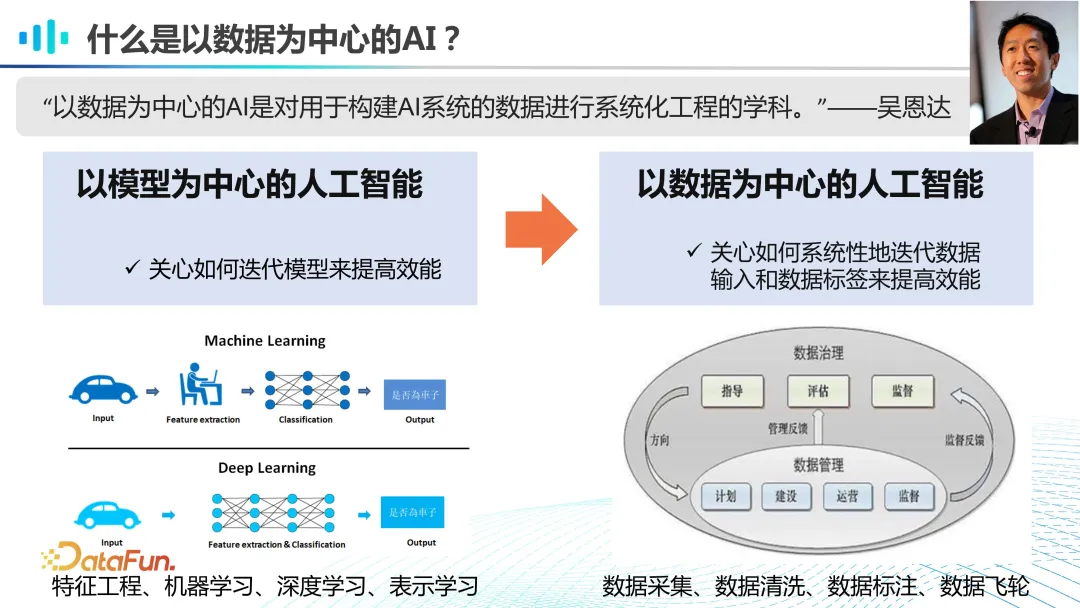
以数据为中心的人工智能,这一理念在 2021 年由吴恩达教授提出,强调了在构建 AI 系统时,对数据的系统化工程处理的重要性。与过去以模型为中心的方法相比,以数据为中心的方法更加注重数据的质量、多样性和治理流程。在早期的机器学习和深度学习时代,我们主要关注特征工程、模型设计和参数制定等方面,但如今,数据的质量和治理已成为决定 AI 系统性能的关键因素。在大模型时代,我们不再需要过多关注特征工程和模型层面的变动,而是将更多的精力投入到数据的治理上,即如何通过有效的数据管理和迭代,使数据发挥更大的价值。
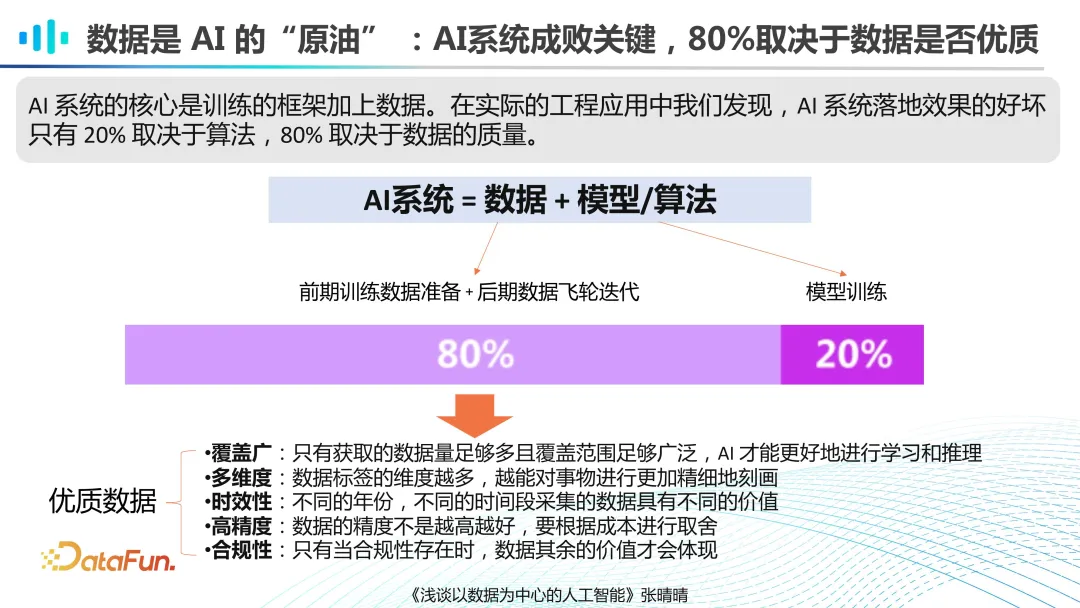
数据是 AI 的原油,AI 系统的成功在很大程度上取决于数据的质量,这一点被广泛认同。一个 AI 系统 80% 的工作量集中在前期的预训练数据准备和后期的数据飞轮迭代上。对于如何定义优质的数据,张博士的论文中提出了几个关键维度:覆盖范围广、维度多样、时效性强、精度高以及合规性好。这些维度不仅反映了小模型对数据的要求,在大模型预训练时代更是显得至关重要。我们需要的是具有多样性和泛化能力的数据,以确保AI 模型在各种场景下都能表现出色。
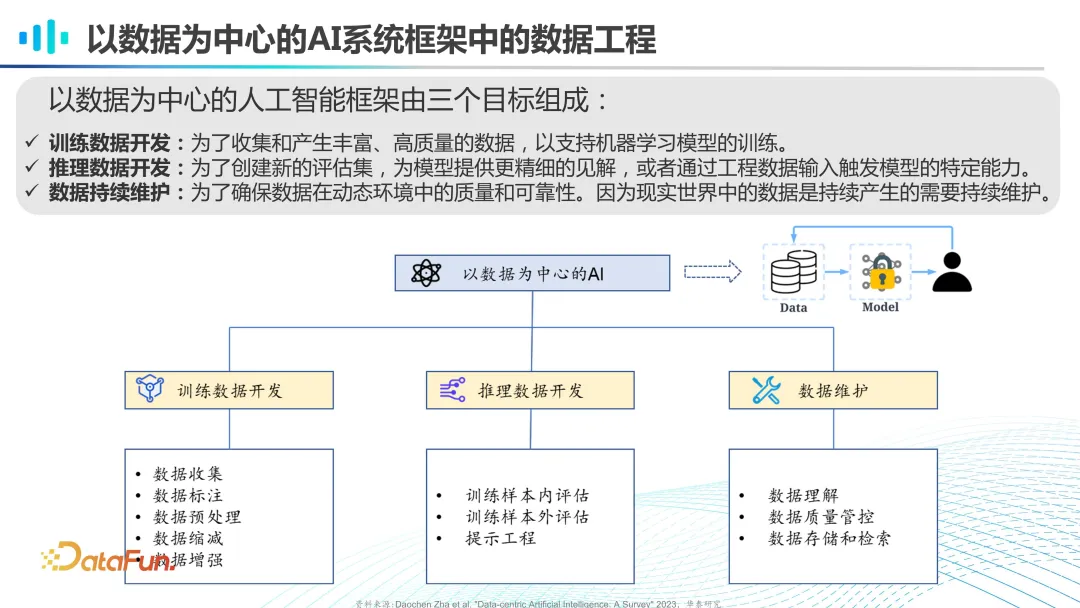
在以数据为中心的 AI 框架中,数据开发通常分为三个阶段:训练数据的开发、推理数据的开发和数据维护。训练数据的开发包括数据的收集、标注和预处理等步骤。推理数据的开发涉及训练样本评估与提示工程等。数据的维护则关注于当后续不断有新数据产生时,对于数据的理解与质量管控,以及数据的存储和检索等任务。以上是以数据为中心的人工智能的整体思路。
02 大模型预训练中的数据工程

在大模型的预训练过程中,数据工程的工作量显著增加。以 GPT 为例,实际训练中使用的数据涵盖了多个层面,我们需要收集大量的语料库,其原始大小为 45TB,清洗完之后剩下 175GB。此外还融合丰富的代码数据及上万个 Prompt 任务参与训练。实际上,成本及创意主要在数据准备上,对于 Transformer 技术的运用,大家的使用方法都大同小异。对于某些特定领域的表达与通用领域存在差异时,如专业术语或符号,我们可能需要进行词表的扩充,以确保模型能够准确地理解这些表达。
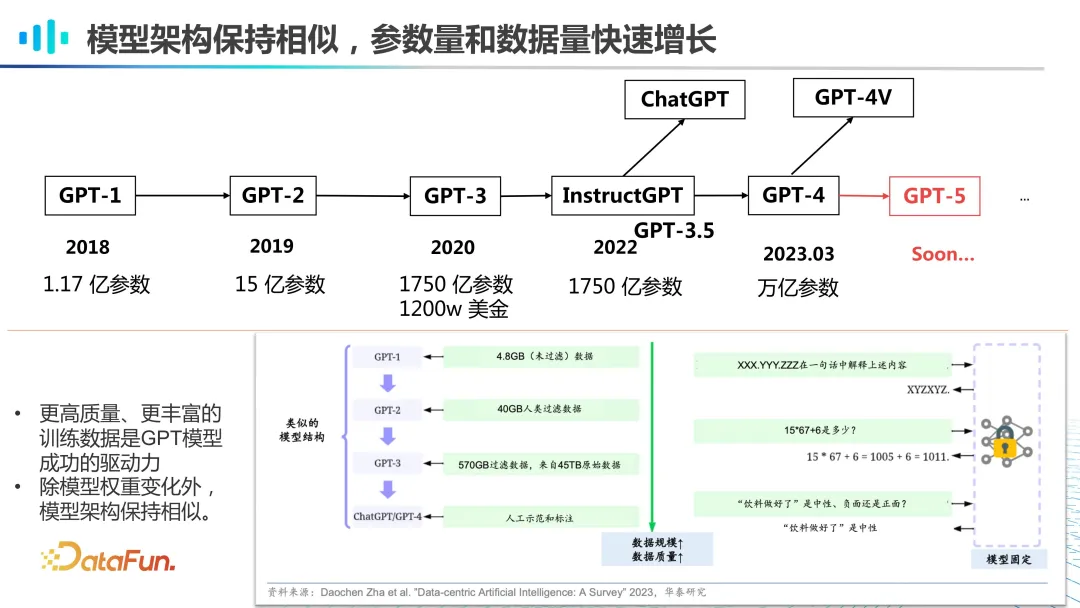
纵观 GPT 的发展历史,从 2018 年到 2020 年,我们不难发现,随着模型参数的逐步增加,数据规模也在同步扩大。例如,GPT-1 虽然只有 1 亿多参数,但它已经使用了 4.8GB 的未过滤数据。到了 GPT-2,参数数量增至 15 亿,数据规模扩大了 10 倍,并且这些数据还经过了人工过滤,进一步提升了数据质量。到了 GPT-3,算力提升了近百倍,数据量也大幅增加,从 45TB 的原始数据中过滤出了 570GB 的数据。因此,尽管参数庞大和算力强大是 GPT 模型的显著特点,但背后的核心在于海量的数据输入。没有足够的数据支持,再强大的算力也难以发挥作用,正所谓“巧妇难为无米之炊”。数据的丰富性和质量对于模型的训练至关重要。另一方面,我们观察到整个模型的架构其实并未发生显著变化。真正在起作用的是 scaling law(伸缩法则),即随着模型规模和数据量的增加,模型的性能也会相应提升。
转载自公众号数据思考笔记