
行业动态
想解决一个困扰企业多年的问题:如何让员工快速找到所需信息?
检索增强生成(RAG)技术有望成为解决这一难题的关键,但如何选择最合适的数据存储方案?
向量数据库?图数据库?还是知识图谱?让我们一探究竟。

向量数据库将文档分成小块(约100-200个字符),通过嵌入模型转化为向量存储。当用户提问时,系统会将问题转换为向量,然后使用KNN(K最近邻)或ANN(近似最近邻)算法找到最相似的内容。
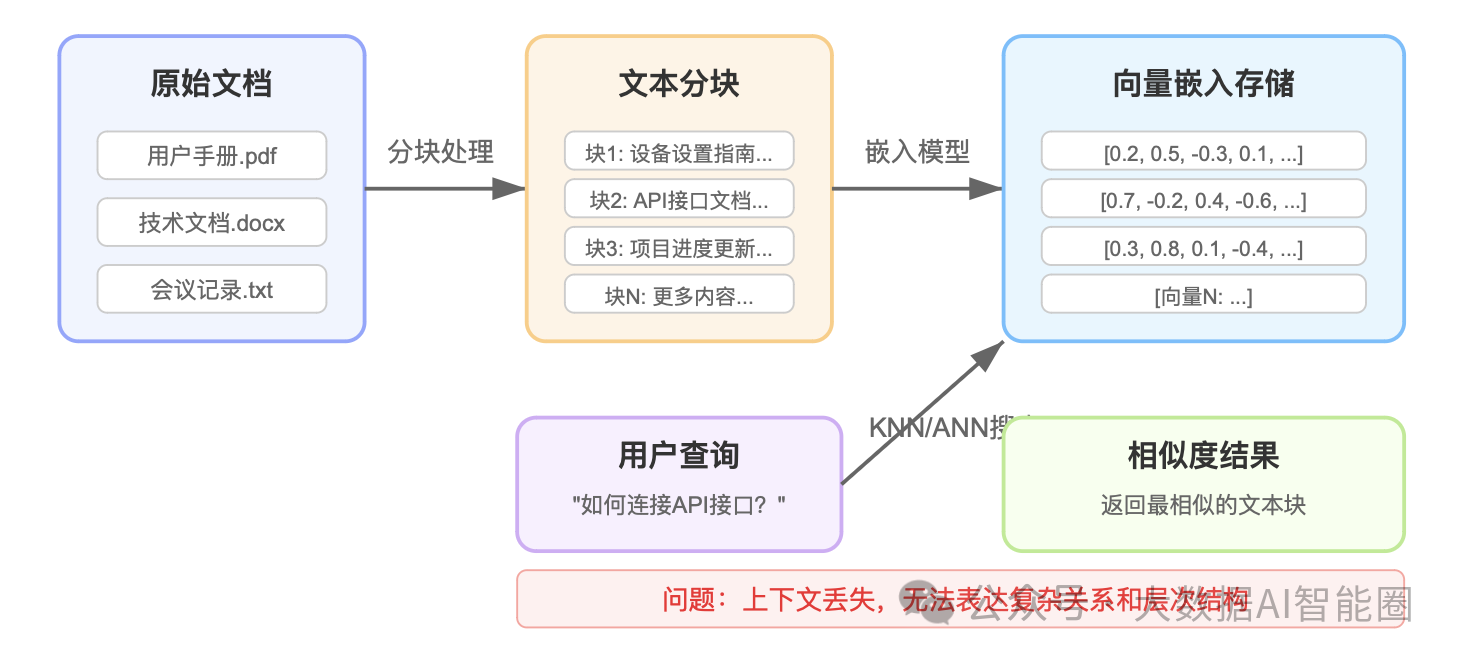
核心优势:
·可以存储多种类型的数据(文本、图像等)
·能够处理非结构化数据
·支持语义相似性搜索,不局限于关键词匹配
关键问题:
上下文丢失。
看一个简单案例:一份关于Apple公司的文档包含"Apple于1976年4月1日成立,由Steve Wozniak和Steve Jobs共同创办...Apple于1983年推出了Lisa,1984年推出了Macintosh..."
当用户询问"Apple什么时候推出第一台Macintosh?"时,向量数据库可能会因为分块和相似性搜索机制,错误地将"1983"和"Macintosh"联系起来,给出错误答案。
图数据库:关系优先但效率欠佳
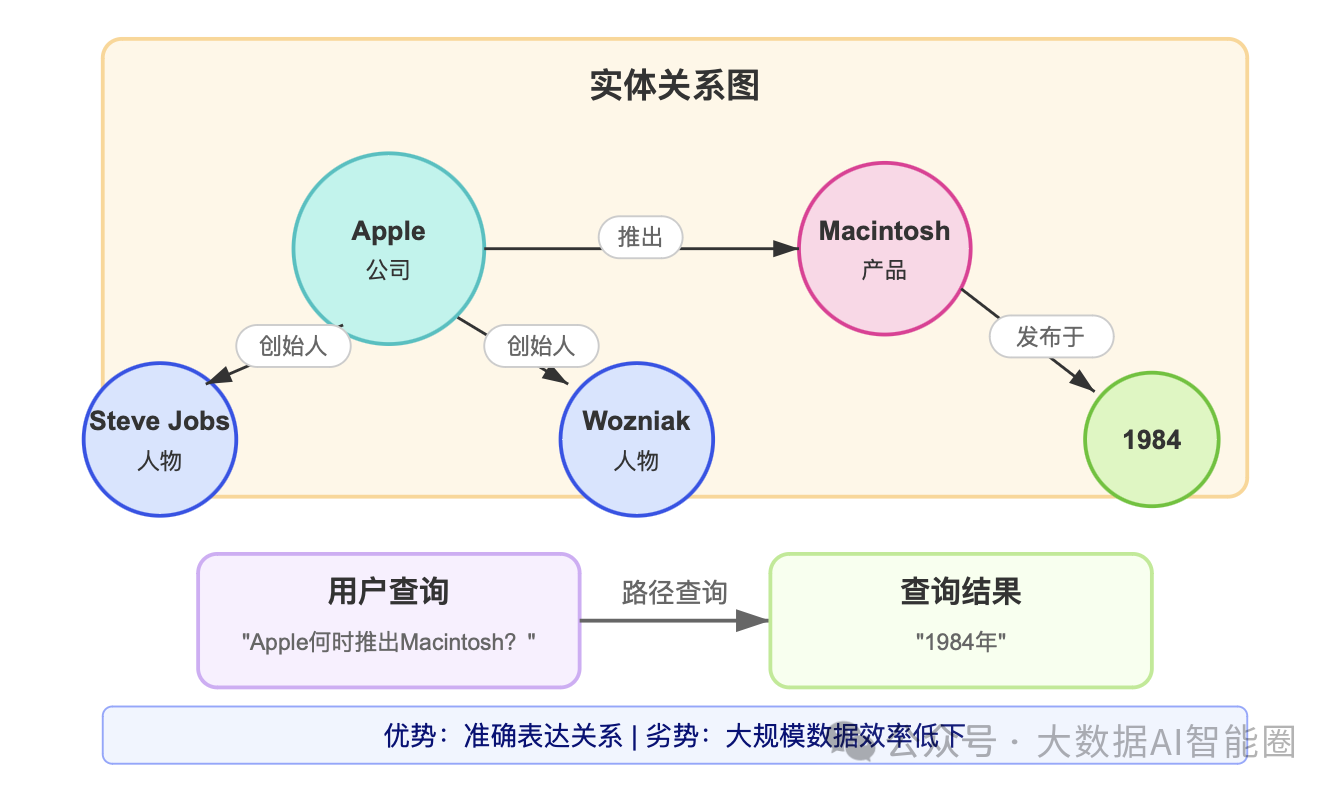
图数据库通过节点和边将数据点组织成关系网络。
每个节点代表一个实体(如人物、公司、产品),而边则代表实体间的关系(如"创建"、"属于"、"推出")。
核心优势:
·直接存储和表示实体间的关系
·允许开发者为关系分配权重和方向性
·结构直观,易于可视化理解
前面Apple的案例在图数据库中会有明显改善。
通过清晰的关系路径(Apple-[推出]->Macintosh-[发布于]->1984),系统能够准确回答"Apple何时推出Macintosh?"
关键问题:
在处理大规模数据时效率低下,尤其是企业环境中的稀疏数据和密集数据混合情况。
跨数据库的扩展查询效果较差,数据库规模越大,查询效率越低。
知识图谱:融合语义与关系的最佳选择
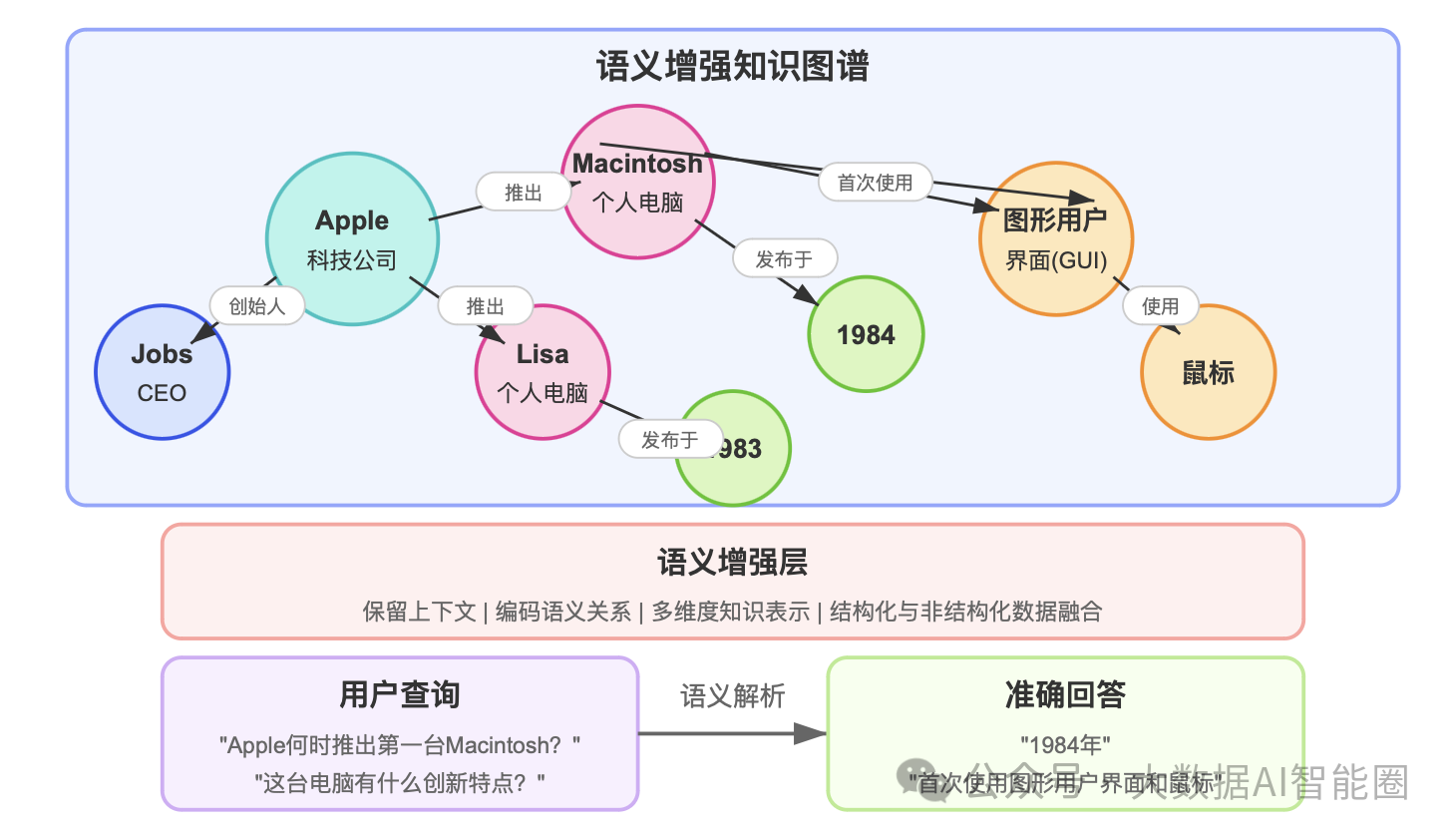
知识图谱不只是另一种数据库技术,而是一种模拟人类思维方式的数据存储技术。
它通过语义描述收集和连接概念、实体、关系和事件,形成一个整体网络。
核心优势:
·保留完整的语义上下文和关系能
·够编码结构关系和层次结构
·支持跨多个来源的数据综合
·更高的查询准确率
研究表明,从基于GPT4和SQL数据库的16%准确率可提升到使用同一SQL数据库的知识图谱表示时的54%准确率,这种差距对RAG系统的可靠性至关重要。
知识图谱将Apple公司案例进一步优化,不仅能回答"Apple何时推出Macintosh?",还能解答"这台电脑有什么创新特点?"等更复杂的问题,因为它保留了产品与其特性之间的关系(如Macintosh首次使用了图形用户界面和鼠标)。
关键挑战:
知识图谱需要大量计算能力支持,某些操作成本较高,可能难以扩展。
企业级RAG的最佳实践:混合架构
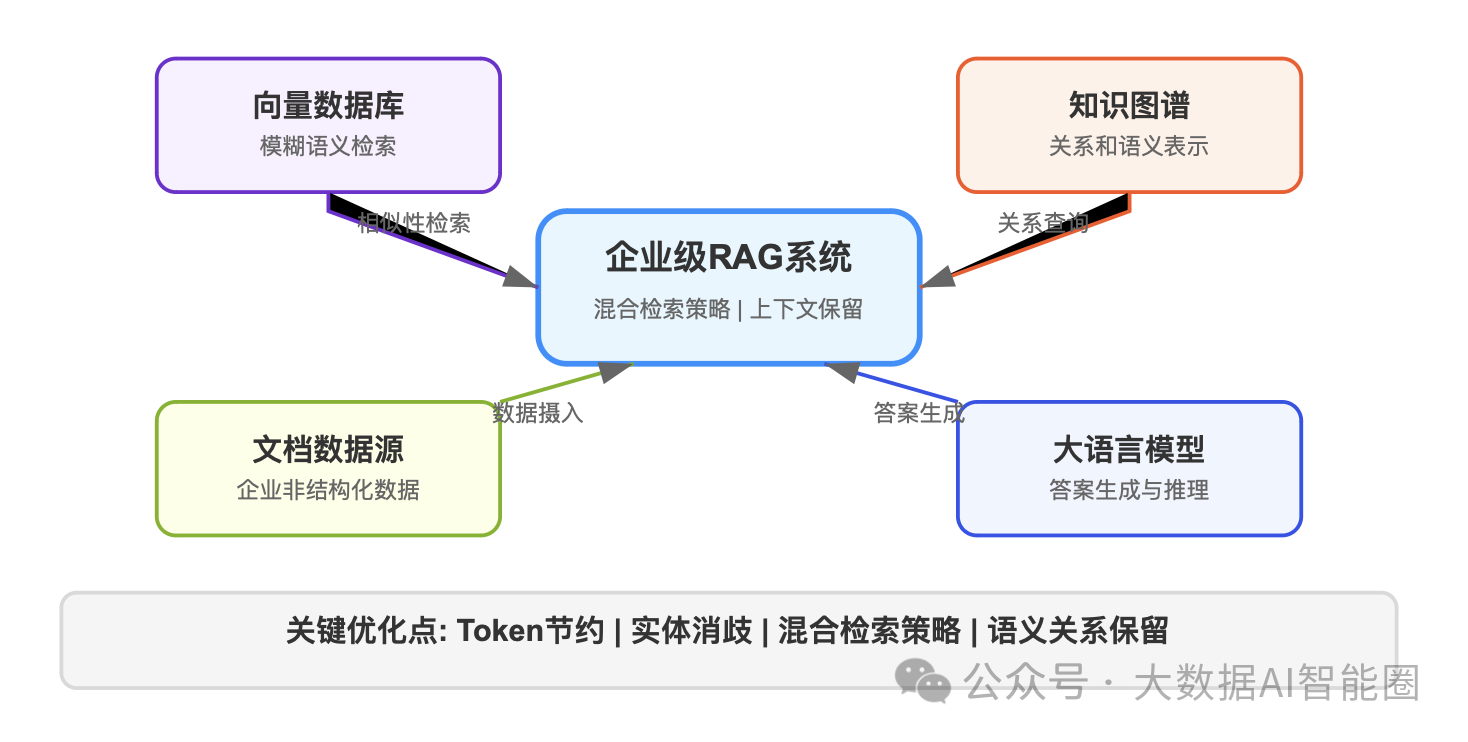
面对企业级RAG的复杂需求,最佳解决方案往往是结合各技术优势的混合架构。
核心策略:
1.混合检索:向量数据库处理模糊语义查询,知识图谱处理结构化关系查询。
2.节约Token:
·图谱裁剪:只返回与问题直接相关的实体和关系
·使用最短路径算法减少返回节点数量
·对结果进行摘要,生成精炼的知识表示
3.实体消歧:
·利用上下文信息增强歧义词的语义表示
·对实体设置类型和属性约束
·通过向量数据库和知识图谱的联合检索,相互验证实体含义
在Apple公司的例子中,混合架构能够更全面地回答用户问题:
·"Apple是什么公司?" → 向量数据库提供概述信息
·"Apple何时推出Macintosh?" → 知识图谱提供精确时间线
·"Macintosh有什么创新特点?" → 知识图谱提供关系信息,向量数据库补充详细描述
企业选择RAG数据存储技术不是一场非此即彼的争夺,而是应基于具体需求和应用场景的综合考量。
对于企业级RAG系统,知识图谱因其保留语义关系和编码结构信息的能力,往往成为首选;而结合向量数据库的混合架构,则能提供最完整、最准确的解决方案。
记住,用户只需一个答案就能继续工作。RAG技术的最终目标是让企业员工能够迅速获取准确信息,不再浪费时间等待答案,不再重复回答相同问题。选择合适的数据存储技术,是企业实现这一目标的关键一步。
转发自公众号大数据AI智能圈